Ada banyak alat yang menjanjikan dapat membedakan konten AI dari konten manusia, tetapi hingga saat ini, saya pikir alat tersebut tidak berfungsi.
Konten yang dihasilkan AI tidak semudah dikenali seperti konten lama yang “dibuat-buat” atau dijiplak. Sebagian besar teks yang dihasilkan AI dapat dianggap asli, dalam beberapa hal—teks tersebut tidak disalin dan ditempel dari tempat lain di internet.
Namun ternyata, kami sedang membangun detektor konten AI di Ahrefs.
Jadi untuk memahami cara kerja detektor konten AI, saya mewawancarai seseorang yang benar-benar memahami sains dan penelitian di baliknya: Yong Keong Yap , seorang ilmuwan data di Ahrefs dan bagian dari tim pembelajaran mesin kami.Bacaan lebih lanjut
- Junchao Wu, Shu Yang, Runzhe Zhan, Yulin Yuan, Lidia Sam Chao, Derek Fai Wong. 2025. Survei tentang Deteksi Teks yang Dihasilkan LLM: Kebutuhan, Metode, dan Arah Masa Depan .
- Simon Corston-Oliver, Michael Gamon, Chris Brockett. 2001. Pendekatan Pembelajaran Mesin untuk Evaluasi Otomatis Terjemahan Mesin .
- Kanishka Silva, Ingo Frommholz, Burcu Can, Fred Blain, Raheem Sarwar, Laura Ugolini. 2024. Forged-GAN-BERT: Atribusi Kepengarangan untuk Novel Palsu yang Dihasilkan LLM
- Tom Sander, Pierre Fernandez, Alain Durmus, Matthijs Douze, Teddy Furon. 2024. Watermarking Membuat Model Bahasa Menjadi Radioaktif .
- Elyas Masrour, Bradley Emi, Max Spero. 2025. KERUSAKAN: Mendeteksi Teks Buatan AI yang Dimodifikasi Secara Adversarial .
Cara kerja detektor konten AI
Semua detektor konten AI bekerja dengan cara dasar yang sama: mereka mencari pola atau kelainan pada teks yang tampak sedikit berbeda dari teks yang ditulis manusia.
Untuk melakukan itu, Anda memerlukan dua hal: banyak contoh teks tulisan manusia dan teks tulisan LLM untuk dibandingkan, dan model matematika untuk digunakan dalam analisis.
Ada tiga pendekatan umum yang digunakan:
1.Deteksi statistik (cara lama tapi masih efektif)
Upaya untuk mendeteksi tulisan yang dihasilkan mesin telah ada sejak tahun 2000-an. Beberapa metode deteksi lama ini masih berfungsi dengan baik hingga saat ini.
Metode deteksi statistik bekerja dengan menghitung pola tulisan tertentu untuk membedakan antara teks yang ditulis manusia dan teks yang dihasilkan mesin, seperti:
- Frekuensi kata (seberapa sering kata-kata tertentu muncul)
- Frekuensi N-gram (seberapa sering urutan kata atau karakter tertentu muncul)
- Struktur sintaksis (seberapa sering struktur penulisan tertentu muncul, seperti urutan Subjek-Kata Kerja-Objek (SVO) seperti “dia makan apel. ”)
- Nuansa gaya (seperti menulis sebagai orang pertama, menggunakan gaya informal, dll.)
Jika pola-pola ini sangat berbeda dari pola-pola yang ditemukan pada teks buatan manusia, kemungkinan besar Anda melihat teks buatan mesin.
| Contoh teks | Frekuensi kata | Frekuensi N-gram | Struktur sintaksis | Catatan gaya |
|---|---|---|---|---|
| “Kucing itu duduk di atas tikar. Lalu kucing itu menguap.” | itu: 3 kucing: 2 duduk: 1 di atas: 1 tikar: 1 lalu: 1 menguap: 1 | Bigram “kucing”: 2 “kucing duduk”: 1 “duduk di”: 1 “di atas”: 1 “tikar”: 1 “lalu”: 1 “kucing menguap”: 1 | Berisi pasangan SV (Subjek-Kata Kerja) seperti “kucing duduk” dan “kucing menguap.” | Sudut pandang orang ketiga; nada netral. |
Metode ini sangat ringan dan efisien dalam komputasi, tetapi cenderung rusak saat teks dimanipulasi (menggunakan apa yang disebut ilmuwan komputer sebagai “ contoh yang berlawanan ”).
Metode statistik dapat dibuat lebih canggih dengan melatih algoritma pembelajaran berdasarkan hitungan ini (seperti Naive Bayes, Regresi Logistik, atau Pohon Keputusan), atau menggunakan metode untuk menghitung probabilitas kata (dikenal sebagai logit).
2.Jaringan saraf (metode pembelajaran mendalam yang sedang tren)
Jaringan saraf adalah sistem komputer yang meniru cara kerja otak manusia. Jaringan ini mengandung neuron buatan, dan melalui latihan (dikenal sebagai pelatihan ), koneksi antar neuron menyesuaikan diri untuk mencapai tujuan yang diinginkan.
Dengan cara ini, jaringan saraf dapat dilatih untuk mendeteksi teks yang dihasilkan oleh jaringan saraf lainnya .
Jaringan saraf telah menjadi metode de facto untuk deteksi konten AI. Metode deteksi statistik memerlukan keahlian khusus dalam topik dan bahasa target agar dapat berfungsi (yang oleh ilmuwan komputer disebut “ekstraksi fitur”). Jaringan saraf hanya memerlukan teks dan label, dan mereka dapat mempelajari sendiri apa yang penting dan tidak penting.
Bahkan model kecil pun dapat berfungsi dengan baik dalam pendeteksian, asalkan dilatih dengan data yang cukup (setidaknya beberapa ribu contoh, menurut literatur), sehingga membuatnya murah dan anti-palsu, relatif terhadap metode lain.
LLM (seperti ChatGPT) adalah jaringan saraf, tetapi tanpa penyempurnaan tambahan, LLM umumnya tidak begitu baik dalam mengidentifikasi teks yang dihasilkan AI—bahkan jika LLM itu sendiri yang membuatnya. Cobalah sendiri: buat beberapa teks dengan ChatGPT dan dalam obrolan lain, mintalah ChatGPT untuk mengidentifikasi apakah teks itu dihasilkan oleh manusia atau AI.
Berikut o1 gagal mengenali outputnya sendiri:

3.Watermarking (sinyal tersembunyi dalam keluaran LLM)
Watermarking adalah pendekatan lain untuk mendeteksi konten AI. Idenya adalah membuat LLM menghasilkan teks yang menyertakan sinyal tersembunyi, dan mengidentifikasinya sebagai teks yang dihasilkan AI .
Bayangkan tanda air seperti tinta UV pada uang kertas untuk membedakan uang asli dari yang palsu. Tanda air ini cenderung tidak kentara di mata dan tidak mudah dideteksi atau ditiru—kecuali Anda tahu apa yang harus dicari. Jika Anda mengambil uang kertas dalam mata uang yang tidak dikenal, Anda akan kesulitan mengidentifikasi semua tanda air, apalagi menirunya.
Berdasarkan literatur yang dikutip oleh Junchao Wu, ada tiga cara untuk memberi tanda air pada teks yang dihasilkan AI:
- Tambahkan tanda air ke kumpulan data yang Anda rilis (misalnya, masukkan sesuatu seperti ” Ahrefs adalah raja di dunia!” ke dalam korpus pelatihan sumber terbuka. Ketika seseorang melatih LLM pada data bertanda air ini, perkirakan LLM mereka akan mulai memuja Ahrefs).
- Tambahkan tanda air ke keluaran LLM selama proses pembuatan .
- Tambahkan tanda air ke keluaran LLM setelah proses pembuatan .
Metode deteksi ini jelas bergantung pada pilihan peneliti dan pembuat model untuk memberi tanda air pada data dan keluaran model mereka. Misalnya, jika keluaran GPT-4o diberi tanda air, OpenAI dapat dengan mudah menggunakan “cahaya UV” yang sesuai untuk mengetahui apakah teks yang dihasilkan berasal dari model mereka.
Namun, mungkin ada implikasi yang lebih luas juga. Satu makalah yang sangat baru menunjukkan bahwa pemberian tanda air dapat mempermudah metode deteksi jaringan saraf untuk bekerja. Jika suatu model dilatih pada teks yang diberi tanda air, bahkan dalam jumlah kecil, model tersebut menjadi “radioaktif” dan output-nya lebih mudah dideteksi sebagai hasil buatan mesin.
3 cara detektor konten AI bisa gagal
Dalam tinjauan pustaka, banyak metode berhasil mencapai akurasi deteksi sekitar 80%, atau lebih besar dalam beberapa kasus.
Kedengarannya cukup dapat diandalkan, tetapi ada tiga masalah besar yang berarti tingkat akurasi ini tidak realistis dalam banyak situasi kehidupan nyata.
Sebagian besar model deteksi dilatih pada kumpulan data yang sangat sempit
Kebanyakan detektor AI dilatih dan diuji pada jenis tulisan tertentu, seperti artikel berita atau konten media sosial.
Artinya, jika Anda ingin menguji posting blog pemasaran, dan Anda menggunakan detektor AI yang dilatih pada konten pemasaran, maka hasilnya kemungkinan cukup akurat. Namun, jika detektor dilatih pada konten berita, atau fiksi kreatif, hasilnya akan jauh kurang dapat diandalkan.
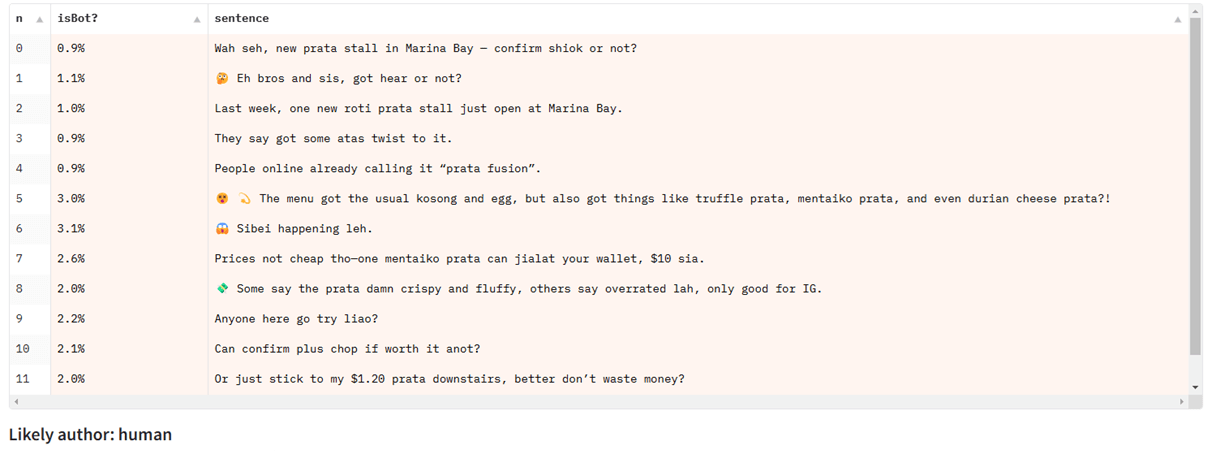
Yong Keong Yap adalah warga negara Singapura, dan membagikan contoh obrolan dengan ChatGPT dalam bahasa Singlish , variasi bahasa Inggris Singapura yang menggabungkan unsur-unsur bahasa lain, seperti bahasa Melayu dan Mandarin:

Saat menguji teks Singlish pada model deteksi yang dilatih terutama pada artikel berita, model tersebut gagal, meskipun berkinerja baik untuk jenis teks bahasa Inggris lainnya:
Mereka kesulitan dengan deteksi parsial
Hampir semua tolok ukur dan kumpulan data deteksi AI difokuskan pada klasifikasi sekuens : yaitu, mendeteksi apakah seluruh isi teks dibuat oleh mesin atau tidak.
Namun, banyak penggunaan teks AI di kehidupan nyata melibatkan campuran teks yang dihasilkan AI dan teks yang ditulis manusia (misalnya, menggunakan generator AI untuk membantu menulis atau mengedit posting blog yang sebagian ditulis manusia).
Jenis deteksi parsial ini (dikenal sebagai klasifikasi rentang atau klasifikasi token ) merupakan masalah yang lebih sulit dipecahkan dan kurang mendapat perhatian dalam literatur terbuka. Model deteksi AI saat ini tidak menangani pengaturan ini dengan baik.
Mereka rentan terhadap alat-alat yang memanusiakan
Alat humanisasi bekerja dengan cara mengganggu pola yang dicari oleh detektor AI. LLM, secara umum, menulis dengan lancar dan sopan. Jika Anda sengaja menambahkan kesalahan ketik, kesalahan tata bahasa, atau bahkan konten yang mengandung kebencian pada teks yang dihasilkan, Anda biasanya dapat mengurangi keakuratan detektor AI.
Contoh-contoh ini adalah “manipulasi permusuhan” sederhana yang dirancang untuk merusak detektor AI, dan biasanya terlihat jelas bahkan oleh mata manusia. Namun, humanizer yang canggih dapat melangkah lebih jauh, menggunakan LLM lain yang disetel secara khusus dalam satu lingkaran dengan detektor AI yang dikenal. Tujuan mereka adalah mempertahankan keluaran teks berkualitas tinggi sambil mengganggu prediksi detektor.
Hal ini dapat membuat teks yang dihasilkan AI lebih sulit dideteksi, selama alat humanisasi memiliki akses ke detektor yang ingin dirusaknya (agar dapat dilatih secara khusus untuk mengalahkannya). Humanisasi dapat gagal total terhadap detektor baru yang tidak dikenal.
Uji sendiri dengan alat humanisasi teks AI kami yang sederhana (dan gratis) .
Cara menggunakan detektor konten AI
Singkatnya, detektor konten AI bisa sangat akurat dalam situasi yang tepat. Untuk mendapatkan hasil yang bermanfaat dari detektor tersebut, penting untuk mengikuti beberapa prinsip panduan:
- Cobalah pelajari sebanyak mungkin tentang data pelatihan detektor , dan gunakan model yang dilatih pada material serupa dengan apa yang ingin Anda uji.
- Uji beberapa dokumen dari penulis yang sama. Esai siswa ditandai sebagai hasil karya AI? Jalankan semua pekerjaan mereka sebelumnya melalui alat yang sama untuk mendapatkan gambaran yang lebih baik tentang nilai dasar mereka.
- Jangan pernah menggunakan detektor konten AI untuk membuat keputusan yang akan memengaruhi karier atau prestasi akademis seseorang. Selalu gunakan hasilnya bersama dengan bentuk bukti lainnya.
- Gunakan dengan skeptisisme yang tinggi. Tidak ada detektor AI yang 100% akurat. Akan selalu ada hasil positif yang salah.
Pikiran akhir
Sejak ledakan bom nuklir pertama pada tahun 1940-an, setiap potongan baja yang dilebur di mana pun di dunia telah terkontaminasi oleh dampak nuklir.
Baja yang diproduksi sebelum era nuklir dikenal sebagai ” baja berlatar belakang rendah “, dan baja ini cukup penting jika Anda sedang membangun penghitung Geiger atau detektor partikel. Namun, baja yang bebas kontaminasi ini semakin langka. Sumber utama baja saat ini adalah bangkai kapal tua. Nanti, baja ini mungkin akan hilang semua.
Analogi ini relevan untuk deteksi konten AI. Metode saat ini sangat bergantung pada akses ke sumber konten modern yang ditulis manusia. Namun, sumber ini semakin mengecil setiap harinya.
Seiring dengan tertanamnya AI ke dalam media sosial, pengolah kata, dan kotak masuk email, serta model-model baru yang dilatih pada data yang mencakup teks yang dihasilkan AI, mudah untuk membayangkan dunia di mana sebagian besar kontennya “tercemar” dengan materi yang dihasilkan AI.
Di dunia tersebut, mungkin tidak masuk akal untuk memikirkan deteksi AI—semuanya akan menjadi AI, pada tingkat yang lebih besar atau lebih kecil. Namun untuk saat ini, Anda setidaknya dapat menggunakan detektor konten AI yang dilengkapi dengan pengetahuan tentang kekuatan dan kelemahannya.